一、显存消耗计算
大模型私有化部署的硬件配置主要取决于模型的规模。较小的模型(如数百万参数)可能只需单个GPU,而大型模型(数十亿到万亿参数)则需要多GPU甚至多机集群。
模型参数量直接影响所需的GPU显存、系统内存和计算能力。
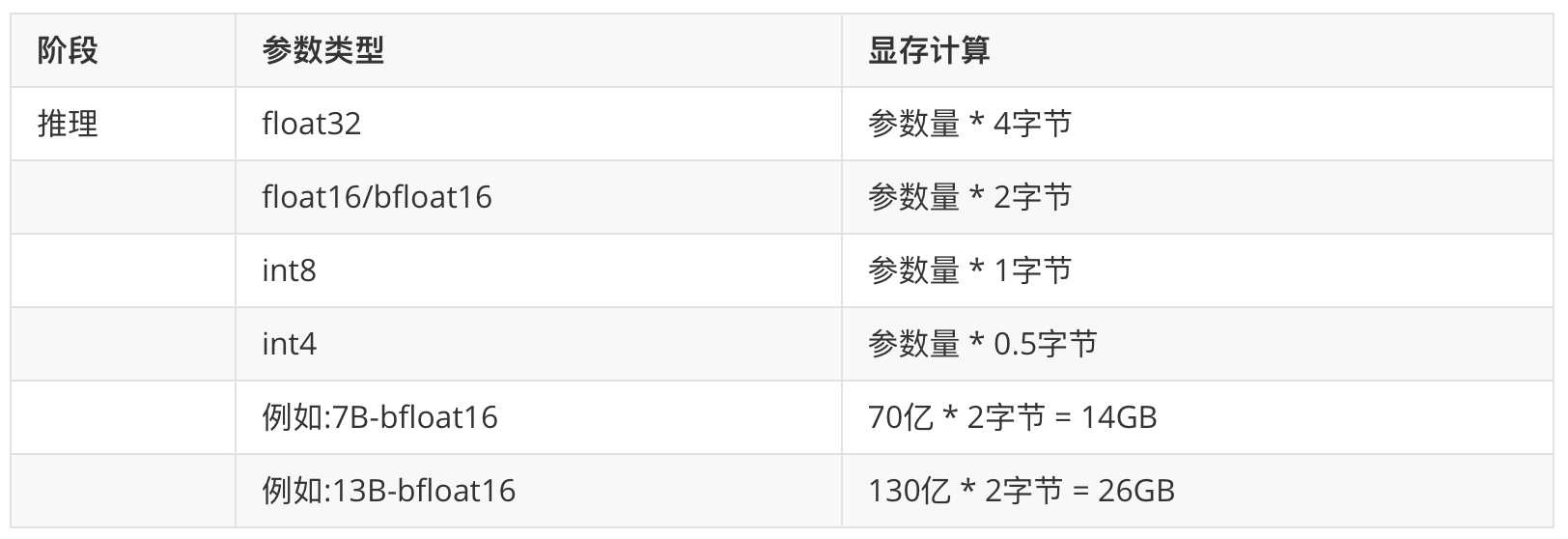
大多数模型参数采用 float32 类型,每个参数占用 4 个字节。
根据经验和粗略估计,模型参数规模X B时,一般推理需要2-3X GB的显存。
二、如何找大模型
- Huggingface:https://huggingface.co/models
- Modelscope:https://modelscope.cn/models
三、如何选择适合的大模型
- 应用场景:希望用大模型解决哪些需求,是否支持图片以及特定领域,对应过滤模型能力
- 性能要求:要求高准确性的任务,可能需要选择更大、更复杂的模型
- 资源限制:大模型通常需要强大的 GPU 支持,评估硬件能力
- 模型规模:和资源正相关,更大规模的模型能力更强,但需要大量资源
- 成本评估:运行模型需要的硬件投资及部分商业模型可能支付许可费
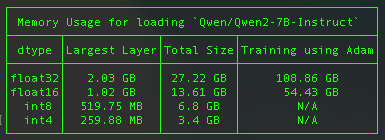
四、Qwen2-7B-Instruct 大模型
Qwen2 系列模型基本能够超越同等规模的最优开源模型甚至更大规模的模型。相比近期推出的最好的模型,Qwen2-7B-Instruct 依然能在多个评测上取得显著的优势,尤其是代码及中文理解上。

不考虑任何量化技术的情况下,预估占用显存 27GB
五、Huggingface 模型显存估算器
Huggingface 提供的 accelerate 工具内置了 estimate-memory 功能,可以帮助快速计算指定模型在不同数据类型下的显存需求。 详见:model_size_estimator